k8s 网络原理入门
之前通过讲 docker compose 教程 初步了解容器编排技术。但是 docker compose 默认只能在单机模式下运行,如果想在多个宿主机上运行,你可以借助 docker swarm 技术,你可以方便的将 docker-compose.yml 文件运用到 swarm 集群创建中。不过由于 kubernetes 的出现,swarm 的市场受到了极大排挤,目前各大公司利用容器编排技术,一般都会选择 kubernetes。本文顺应时势,在讲解容器编排技术的时候也是选择了 kubernetes 作为入门教程。本文作为教程的第一章,选择主要讲解的 kubernetes 内部网络原理。
本文原始链接:https://blog.whyun.com/posts/k8s-startup/ ,转载请注明出处。
1. 安装
1.1 Linux 下安装
可以参见这篇文章 使用kubeadm搭建k8s集群-ubuntu/debian发行版 。
1.2 Windows 下安装
可以参见我之前的博文 docker desktop 下配置 kubernetes 。
2 原理
kubernetes 将若干容器进行编排,形成一个集群,但是这个集群最终要对外提供访问能力,才能被使用。kubernetes 自带了 NodePort 和 LoadBalancer 两种模式来让使用者从外部访问集群内的机器。其中 NodePort 和原理和我们路由器中用到的网络地址转化(Network Address Translation,简称 NAT)是一样的。kubernetes 会对外提供一个端口,用来支持外部应用来访问内部的某一个服务。同时对于内部 pod 来说,每个部署当前服务的节点都会被分配一个特定端口,用来接收“路由器”转发过来的请求。
pod 是 kubernetes 中的管理单元,其代表集群中一组正在运行的容器。所以说 kubernetes 集群和 pod 之间的数量级关系是 1:N,而 pod 和容器之间的数量级关系是 1:M。
对于外部访问者来说,它看到的一个服务的访问地址是“路由器”的IP,定义为 IPV,定义在这个“路由器”上的一个指定端口,定义为 PORTD,记这个服务本身为 SERVICEX。“路由器”在读取到这个数据时,首先读取网络层数据包的头部信息,这样就拿到了请求者的源地址。然后读取网络层正文部分数据的前四个字节,也就是传输层的头部信息的前四个字节,这样就得到了请求者的源端口,和它要访问的目的地的端口(也就是 PORTD)。
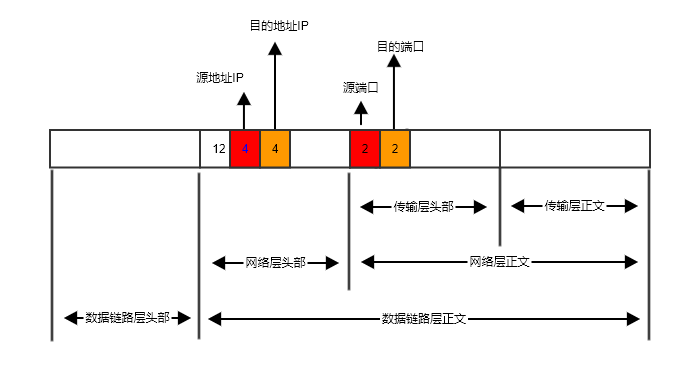
图 2.1
图 2.1 中橙色的 2 字节的内容即为请求数据的目的端口号,也就是上面我们说到的 PORTD 的值,“路由器”识别到当前请求的端口是 PORTD 的时候,就知道用户是要访问 SERVICEX。然后它就去查找当前 SERVICEX 中部署的节点列表,从中挑选一个,记为 Node1,将请求数据包转发给这个 Node1,不过再转发前会将目的 IP 改为 Node1 的 IP,将目的端口号改为 Node1 上这个服务的监听端口号。
Node1 在处理完成之后,将数据包返给“路由器”,源地址写的是 Node1 的 IP,“路由器”收到数据包之后,将源地址改成自己的 IP,转发给请求者。
![]()
图 2.2
整个 NAT 过程如上图所示。
考虑到高可靠性的问题,一个服务不可能部署为单节点,为了展示数据流向,我们在 图 2.2 只画了一个节点,实际情况应该是多个节点(对于 kubernetes 来说,这个 “节点” 就称之为 pod)的拓扑结构。而在 kubernetes 中我们并不是需要一台专门的机器做路由,我们的路由被内置到了集群中的没一台机器中,对于集群中的每个服务来说在系统中都会映射出一个 虚拟 IP。用户编写代码如果要连接一个特定服务,只需要提供虚拟 IP 和服务端口号即可,内核层会自动查找到当前 虚拟 IP 对应的某一个 pod 节点,把你的网络数据包转发过去。这个转发过程,全都是在一台主机上完成的(橙色区域写的内核空间,由于我们描述的是一台主机的情况,所以各个 pod 是共享的内核。里面画了一个路由器,但是仅仅是用来类比路由表的功能。),效率比较高。上面所说的转发,也就是完成了 图2.2 中的第 2 步。Pod1 在处理完数据进行回包的时候,将数据交给内核,内核同样需要修改数据包中的源地址(IPV)和源端口号(PORTD),也就是步骤 4 这个过程,不做这个修改 client 会不识别这个回包。PodClient 的内核态具体选择哪个 pod,kubernetes 内置了若干算法,比如说 Round-Robin Least Connection,更多说明参见算法链接(使用 IPVS 模式时支持若干算法,但是使用 iptables 时,只支持 Round-Robin 算法)。
真实的情况下,kubernetes 集群中肯定会部署多台主机,网络情况比当前举例的要更复杂。简单起见这里仅仅描述一台主机的情况。

图 2.3
同时由于集群内部服务的 pod 个数是动态增减的,这样才能灵活应对流量的激增和回退。所以图 2.3 中的路由表信息如果写死肯定不能应对这种情况。kubernetes 中使用 etcd 来存储数据,它通过 raft 一致性算法来保证数据一致性。一个关联的 pod 有增减之后,就会更改 etcd 数据,kubernetes 中的 kube-proxy 程序会自动监听节点变动,然后把同步修改主机上的 iptables(或者 IPVS 信息)。

图 2.4
前面讲的是单主机的情况,但是正式环境的 kubernetes 集群,都是有若干主机组成的。同一主机上的 pod 们是通过网桥进行转发的。上面的讲解中并没有明确主机和 pod 之间的通信细节,如果展开讲的话,其网络拓扑模型是这样的:
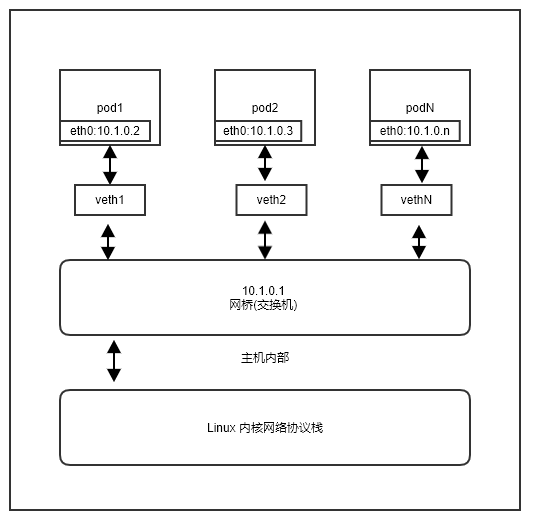
图 2.4
pod 和主机之间 通过 veth pair 技术 进行通信,veth pair 类似于管道,一端发送的数据,可以在另一端收到。如果是统一主机上的 pod 们相互通信,就可以借助于网桥。网桥工作在链路层,可以将其理解为现实中的交换机,veth 网卡和网桥之间的连接,可以理解为网络终端通过网线和交换机之间的连接。网桥内部存储每个网口对应的 MAC 地址映射表,数据链路层的数据包到达网桥后,通过查询映射表就可以准发到对应接口了。
然而 Linux 下的网桥,并不是一个纯粹的交换机,交换机或者说传统意义上的网桥只工作在数据链路层,但是 Linux 下的网卡是一块虚拟网卡,上面可以分配 IP,所以它还可以工作在网络层。它的名字叫“网桥”,仅仅是 Linux 内核开发者的自定义称谓而已。
挂载在主机 1 上的 pod 们,ip 可以是 10.1.0.0/24,但是挂载到主机 2 上的 pod 们,就不能选用跟他们同一网段,否则就很有可能出现地址冲突的问题。我们假定 主机 2上的 pod 们 ip 地址是 10.2.0.0/24。那么这两部分 pod 是不能直接通信的,不过跨网络通信也不是不可能的,我们常用的 VPN 技术就是一种跨网络通信的技术。隧道的原理是,鉴定两个异地的局域网不能相互通信,但是两个局域网所在的网络中都有公网出口,则可以构建了一种隧道技术,将数据链路层的包,外层包裹在传输层中,通过公开网络进行传输,然后到达对端后在提取出内层链路层的包,转发给对应的内部网络终端。所以从抽象一样上看,感觉像是两个局域网是可以在数据链路层相互可见的,但是其实是借助了上述的隧道技术。具体到 kubenetes 中, Flannel、calico、weave 等技术提供了类似隧道功能。由于 kubenetes 中各个主机之间是可以互通的,主机所在的局域网也就成为了刚才流程中的“公开网络”。

图 2.5
参考资料
- LVS负载均衡(LVS简介、三种工作模式、调度原理以及十种调度算法) https://blog.51cto.com/u_14359196/2424034
- Cracking kubernetes node proxy (aka kube-proxy) https://arthurchiao.art/blog/cracking-k8s-node-proxy/
- linux内核网络协议栈–linux bridge(十九)https://blog.csdn.net/qq_20817327/article/details/106843154