Node 缓存优化之路
当今互联网,越来越往大数据的方向发展。大数据的背后是大用户,你的后端服务必须得有能力承载大用户、高并发的冲击。从宏观上讲,提高并发能力,无怪乎横向扩展(增加服务器节点个数)、纵向扩展(提高单点服务器的处理能力)。横向扩展,常见的有负载均衡,是一种部署的拓扑结构;纵向扩展,更多的体现的在应用程序本身性能提升。计算机中,我们常用拿空间换时间,来提升程序性能,缓存正是这种思想的体现。
本文链接地址 https://blog.whyun.com/posts/node/the-cache-design-in-node ,转载请注明出处。
我们这篇文章讲 Node 的缓存设计,不过在切入正题之前,我还是要先讲一下 Node 的线程模型,如下图:
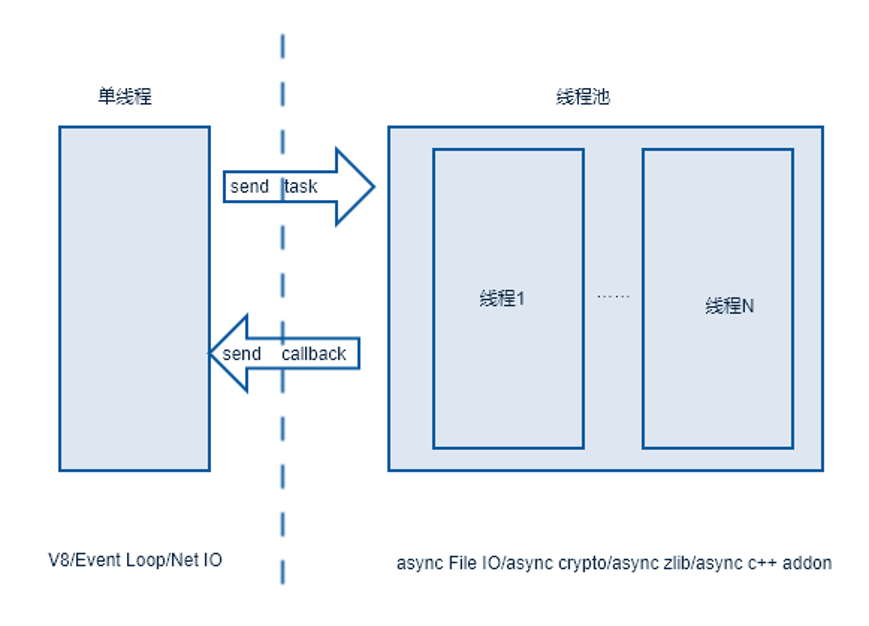
图片0.1 Node 线程模型
我们常说 Node 是单线程程序,这是由于我们 JavaScript 代码(基于 V8 引擎)正是运行在这个单线程中的,此外我们常说的事件轮询、网络 IO 都是运行在这个线程中的。不过 Node 进程中,并不仅仅只包含这一个线程,它还有一个线程池,用来处理 文件 IO 、crypto 、zlib,还有异步 C++ 模块等操作,只不过,我们平常在 Node 中运用这些操作比较少。
1. 缓存分类
从生命周期上讲,缓存大体上分以下三类,
会话 跟用户登陆状态关联的数据,生命周期长
临时数据,短时间内有效,生命周期短
镜像 数据库的数据镜像,生命周期特长
2. 缓存设计思路
2.1 会话
现如今,各种设备终端兴起,很多情况下,我们要自己设计用户会话,而不是直接使用传统 web 中使用的 session,以便更好的适配多端设备,并且能够更好的对性能进行调优。
一个简单的 session 设计思路,就是生成一个 token,然后将用户数据序列化成 JSON 字符串,最后将 token 和 JSON 字符串的映射关系写入 redis。在读取的时候,根据 token 查询到 JSON 字符串,然后反序列化即可。
咋一看,这个设计是没有问题的,不过经过性能测试发现,Node 中 JSON 的反序列化性能是不高的,解决这个问题也很简单,我们将 redis 中反序列化的数据缓存到内存即可,这样用户下次请求的 token 验证就直接走内存了。
不过这又会导致一个问题,如果你的用户量数据巨大,那么内存是不够用的。我们必须得有内存清理机制,否则早晚内存会炸掉。
应该怎么清理呢?每天凌晨将内存中的数据清理掉,但是如果白天内存就告急了怎么半?限制内存存储数据个数,在达到内存限制个数后,内存中存储的都是老数据,如果这些老数据都是冷数据,新来的请求还算是会频繁的请求 redis ,做反序列化。
怎么办?有没有既限制内存数量,且又能读写热数据的思路呢?还真有,这就是 L(Least)R(Recently)U(Used) 算法.。不过如果你使用 JavaScript 编写一个 LRU 算法,就会在 V8 引擎中引入一个耗时操作,这在 Node 中是大忌。我们开头图0.1讲过,Node 进程中其实是有一个线程池的,我们何不将这个 LRU 实现代码,在这里实现?
我写了一个 c++ addon 来处理这个 LRU 算法,刚开始测试的时候性能很不错,看上去完美的解决了这个问题。不过随着时间的推移,我最担心的事情还是发生了,就是进程崩溃了!刚才我们说过,我们借用的是线程池来处理 LRU 算法,但是我们的程序中对于多线程操作,并没有加锁,导致处理的过程中出现脏数据,然后读写非法内存地址,进程就崩溃了。
我将线程操作加上了锁,加锁所导致的性能又一步做出了损耗,但依然在可控范围内。但是我们依然忽略了一个问题,我们做 LRU 就是要减少内存使用的,但是现在我们反而把 每个用户的 token 数据都写到内存中 LRU 关联的链表中,长此以往,内存依然会爆。
说到这里,我们的优化之路,貌似进入了死胡同,不过当你为一件事情殚精竭虑的时候,上天一定会眷顾你。一个偶然的机会,我发现了 Redis 的内存清理也是使用 LRU 算法的,同时在启用 LRU 时,性能也会下降,这跟我们使用LRU算法的结果是一样的。不过在 Redis 中还有一种算法,用来清理过期key,就是定期遍历 key 列表,从 key 列表中取出 N 个 key,判断其是否过期,如果过期,就删除。Redis 也是单线程,其线程模型和 Node 是类似的,所以它在遍历列表的时候,不会做全量遍历,而是使用定时器。增加定时定量的清理算法后,做性能测试,性能并没有损耗,同时还保证了内存占用在可控范围之内。
以上就是会话类型的缓存设计历程,对应的源代码已经开源,参见 session-token。
2.2 闪存
使用闪存,一定是我们允许在短暂时间内缓存数据和真实数据有一定的误差,但是这个误差一定要在允许的范围之内。比如说做阈值处理时,通过 Redis 的 incr 操作做计数器,在达到阈值时就可以把这个值缓存到内存,在达到阈值的短暂时间内,真实的计数器的值我们并不关心。
整个设计思路类似于 JVM 或者 V8 的新生代 GC 算法:
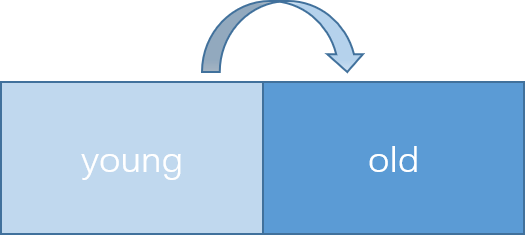
图 2 .2 young/old
缓存数据在写入的时候,现如 young 区域,程序内置定时器每隔固定时间将 young 区域赋值到 old 区域,同时清空 young 区域。
使用时要注意缓存击穿问题。比如说笔者曾经犯过的一个问题,在将 Redis 的查询的结果缓存到闪存,但是如果查询结果为空,没有将空的这个结果缓存下来,所以说对于 key 值不存在的情况,每次都是缓存不命中中的,每次都会请求 Redis。解决的问题也很简单,就是在闪存中保存一个空串。
对应的源代码解决方案参见 flash-cache。
2.3 镜像
前段时间,我们接手了一个 IM 项目,要求实现类似于钉钉的功能,在线可以实时接收数据,离线后上线,可以查看未读历史记录。考虑到是一个实时系统,我们的没有选择直接读取 mongodb,而是将数据先写入 Redis 中。同时将实时聊天记录打入 Kafka,然后通过消费者程序同步到 mongodb。Redis 中存储的数据可以理解成 mongodb 中的镜像,读取的时候,先读取 Redis,只有在 Redis 中查询不到的时候才读取 mongodb (实际上这种情况几乎不可能发生,因为我们在 Redis 中缓存失效时间很长)。
镜像中一般用来映射数据库中的表记录,采用的 key 类型为 sorted set。但是数据库中的数据量是巨大的,全部缓存到一个 key 中,对于 Redis 是不友好的,所以说需要按天拆分 key。
前面说到 key 的类型为 sorted set,那么 score 是什么呢?score 是一个自增数字,我们用自增数字来唯一标识一条聊天记录。者个自增数字使用的是 Redis 的 incr 操作客户端本地存留一个上次阅读到的聊天 Id,服务器端可以根据上次阅读Id,就可以给客户端返回历史记录(操作过程中会涉及到分页查询)。
3. 性能测试
关于性能调优的方法和工具,可以参见我写的《Node 基础教程》中的第11章 Node 调优。